
Diagnostic Modeling
For Educational and Psychological Assessment
Acknowledgements
The research reported here was supported by the Institute of Education Sciences, U.S. Department of Education, through Grant R305D210045 to the University of Kansas. The opinions expressed are those of the authors and do not represent the views of the the Institute or the U.S. Department of Education.


- Traditional assessments and psychometric models measure an overall skill or ability
- Assume a continuous latent trait
Diagnostic music assessment
- Rather than measuring overall musical knowledge, we can break music down into set of skills or attributes
- Songwriting
- Production
- Vocals
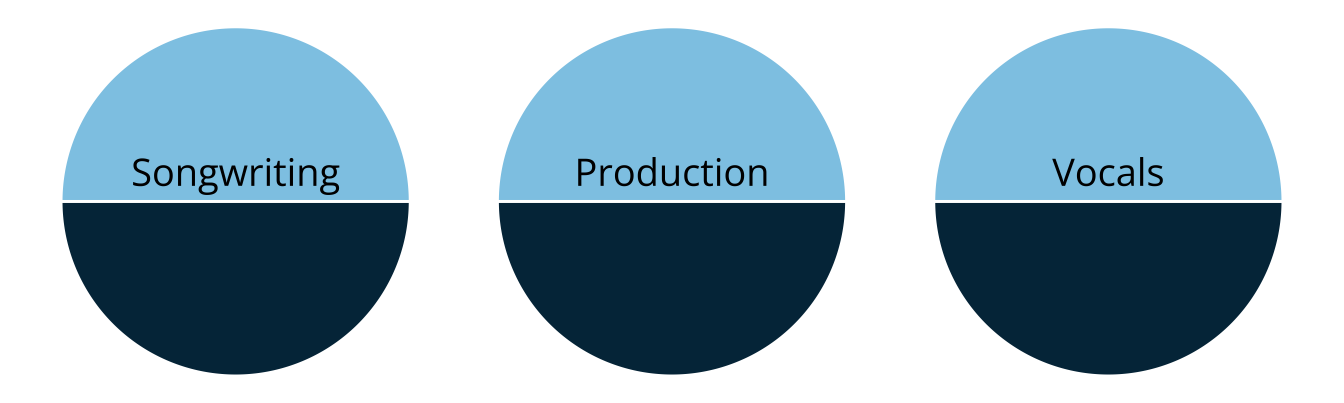
- Attributes are categorical, often dichotomous (e.g., proficient vs. non-proficient)


Probabilities to profiles
| album | songwriting | production | vocals | |
|---|---|---|---|---|
Taylor Swift |
 |
|||
Fearless |
 |
|||
Speak Now |
 |
|||
Red |
 |
|||
1989 |
 |
|||
reputation |
 |
|||
Lover |
 |
|||
folklore |
 |
|||
evermore |
 |
|||
Fearless
Taylor's Version
|
 |
|||
Red
Taylor's Version
|
 |
|||
Midnights |
 |
|||
Speak Now
Taylor's Version
|
 |
|||
1989
Taylor's Version
|
 |
|||
THE TORTURED POETS |
 |
- No scale, no overall “ability”
- Feedback on specific skills as defined by the cognitive theory and test design
Fine-grained feedback
- Distinguish between respondents who may have similar scale scores
| album | songwriting | production | vocals | |
|---|---|---|---|---|
Fearless |
|
|||
Speak Now |
|
|||
Red |
|
|||
reputation |
|
|||
Lover |
|
|||
evermore |
|
|||
Fearless
Taylor's Version
|
|
|||
1989
Taylor's Version
|
|
When are DCMs not appropriate?
When the goal is the ordering of individuals on a scale
DCMs do not distinguish within classes
| album | songwriting | production | vocals | |
|---|---|---|---|---|
Red |
|
|||
Red
Taylor's Version
|
|
Learn more about DCMs


Learn more about measr
Thank you!
Slides
